Закон Мура против нанометров 2
Всё, что вы хотели знать о микроэлектронике, но почему-то не узнали…
2000-е
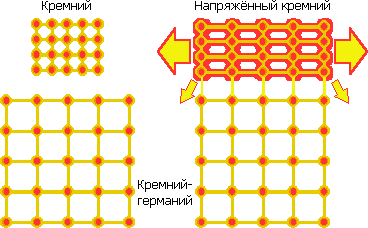
Кремний до и после осаждения на кремний-германиевый слой.
В 2001 г. IBM изобретает напряжённый кремний (strained silicon) —
формирование слоя кремния для канала, в котором расстояние между атомами
(как минимум в направлении исток-сток) не равно естественному шагу
кристаллической решётки (543 пм). Для большего шага сначала внедряется
«посевной» слой кремния-германия. Кристалл германия имеет шаг атомов 566
пм (именно из-за большей подвижности носителей заряда его первым стали
применять в электронике). Смешанный полупроводник сохраняет это
значение, даже если доля германия всего 17% (это для 90 нм; а для 32 нм —
уже 40%). Осаждаемые поверх атомы кремния межатомными силами крепятся к
атомам широкой решётки и остаются с её шагом, формируя затвор.
Разряжение атомов увеличивает подвижность электронов, что ускоряет
транзистор на 20–30%.
В 2004 г. эту технологию применили Intel и AMD для техпроцесса 90
нм. Для 65 нм внедрена ионная имплантация германия и углерода в исток и
сток. Германий раздувает концы транзистора, сжимая его канал, что
увеличивает скорость дырок (т.е. основных носителей заряда в p-канальных
транзисторах). Углерод, наоборот, сжимает исток и сток, что растягивает
n-канал, увеличивая подвижность электронов. Также весь p-канальный
транзистор покрывается сжимающим слоем нитрида кремния.
Шаблонирование распорками (сверху вниз): формирование первичного шаблона
фоторезистом (оранжевый), осаждение химической маски (зелёная),
формирование распорок травлением, удаление резиста, травление рабочего
слоя (синий), удаление распорок.
В 2006 г. только что внедрённый техпроцесс 65 нм уже не мог
основываться лишь на вычислительной литографии, т.к. с длиной волны 193
нм её уже не хватало. Решение, основательно обновившее мировое
чипостроение — множественное структурирование, более известное по своей
простейшей реализации — двойное структурирование (double patterning).
Это семейство технологий снижает минимальный экспонируемый размер
увеличением числа экспонирований. Как правило, в самых современных
техпроцессах применяются несколько приёмов из этого арсенала.
Самосовмещёные распорки (self-aligned spacers) позволяют получить
вдвое большее разрешение формируемого рисунка при той же технорме:
вначале на боковые стенки фоторезиста налипает специальная химическая
маска, используемая далее как финальный шаблон травления после удаления
резиста. Разумеется, этот приём можно повторять и далее, используя
вторичный шаблон для изготовления третичного с ещё вдвое большим
разрешением — насколько это позволит химическая устойчивость материалов и
повторяемость процессов.
Второй случай, требующий применения нового резиста, — двойное
(кратное) экспонирование (double (multiple) exposure): вторая маска
экспонируется на тот же резист со смещением относительно первой на
величину технормы, причём пластина даже не покидает литограф. Чтобы
второй рисунок добавился к первому (а не частично наложился на него),
требуется, чтобы оба раза формировались детали шириной меньше технормы.
Таким образом, например, формируются линии металла и поликремния —
сначала все «вдоль», потом все «поперёк». Замена двухмерного рисунка
двумя одномерными упрощает его нанесение.
Ещё один вариант двойного экспонирования (применяется начиная с
32 нм) использует два разных вида резиста. Второй наносится на рисунок,
сформированный в первом, облучается через вторую маску, после чего
удаляется незафиксированная часть второго резиста, но так, чтобы не
повредить рисунок первого. И тут нужна продвинутая химия — новые
резисты, боковое травление для уменьшения ширины и пр. Зато,
теоретически, такая методика позволяют формировать сколь угодно мелкие
детали. Например, 22-нанометровые элементы могут получаться перемежением
двух масок на 45-нанометровом литографе, трёх масок на 65- или четырёх
на 90-нанометровом. Т.е. текущий техпроцесс можно «разогнать» до
следующего за счёт увеличения числа масок и производственных стадий — с
очевидным удорожанием стоимости завода и внедрения производства новых
микросхем. Но с недавних пор это всё равно оказывается дешевле
«честного» уменьшения технормы через литографию.
Очевидными недостатками кратного экспонирования является кратное
увеличение числа масок и технологических операций для формирования
каждого критического слоя, а также очень высокие требования по точности
совмещения масок. Небольшое смещение между двумя экспозициями слоя может
привести, например, к асимметрии истока и стока (относительно затвора) у
всех транзисторов пластины.
В 2006 г. появилось ещё одно улучшение — погружённая литография.
Впрочем, в крайне неустойчивой и неполной русскоязычной терминологии по
странной традиции прижилась транслитерированная форма оригинала —
иммерсионная литография. Суть оной в том, что пространство между
последней линзой и экспонируемой пластиной заполняется не воздухом, а
жидкостью (на данный момент — водой). Это улучшает разрешение на 30–40%
ввиду большего преломления жидкости, которое влияет на вышеуказанный
параметр NA, равный 1 для воздуха и 1,33 для воды. Intel внедрила
иммерсионную литографию вместо «сухой» с техпроцесса 32 нм, а AMD — ещё с
45 нм. Интересно, что первые «водные» сканеры появились ещё в 2005 г.,
но техпроцессы с ними пришлось дорабатывать около года после внедрения
на фабах до применения в массовом производстве. И вот почему:
Мало того, что вода должна быть сверхчистая (она и так требуется
почти в половине технических процессов производства ИС) — в ней не
должно быть пузырьков, температура должна быть равномерной, она не
должна загрязняться и поглощаться фоторезистом (сверх меры) или
растворять его. Более того, 193-нанометровый ультрафиолет ионизирует
воду — а электроны могут среагировать с фоторезистом. Решить все эти
вопросы удалось внесением специального оптически прозрачного
гидрофобного защитного покрытия для фоторезиста перед экспонированием.
Таким образом плотность дефектов осталась примерно та же.
Не менее важная часть — производительность, ведь мало
изготавливать чипы сложными и дешёвыми, их нужно много. Скорость
пластины в литографическом сканере достигает 0,5 м/с, но держать её всю
под слоем воды не выйдет — сверхточное позиционирование полагается на
лазерные интерферометры, и малейшая рябь на поверхности воды всё
испортит. Поэтому слой «привязали» к оптике. Чтобы пластина не уносила
воду в сторону, вокруг оптики разместили водяные микросопла, половина из
которых по ходу движения впрыскивают воду, а противоположные им —
высасывают. Всё это происходит с очень точным контролем, чтобы не внести
пузыри при впрыске и не оставить позади капли после отсоса, что
особенно трудно с краю пластины. Теперь ясно, почему иммерсионный сканер
гораздо дороже сухого.
В 2007 г. (для техпроцесса 45 нм) в микроэлектронике появилось
сокращение HKMG — High-k [dielectric and] Metal Gate, т.е. изолятор с
высокой диэлектрической проницаемостью и металлический затвор. Сначала о
первой половине формулы. Параметр k означает относительную
диэлектрическую проницаемость (безразмерную величину, разную для разных
веществ), однако в английском языке (и, к сожалению, в большинстве
русских переводов) её почему-то называют диэлектрической константой. (Не
говоря уже о том, что вместо «k» должна быть греческая буква каппа —
κ…) Настоящая же диэлектрическая константа (она же — электрическая
постоянная, ε0), как и полагается, неизменна. В микроэлектронике
«нормальным k» считается 3,9, что соответствует проницаемости диоксида
кремния (SiO2), десятилетия использовавшегося в качестве боковых,
межслойных и подзатворых изоляторов. Вещества с проницаемостью выше 3,9
относятся к классу high-k (высокопроницаемые), а ниже — к low-k
(низкопроницаемые).
Последние нужны для межслойных и боковых диэлектриков, т.к. таким
образом можно лучше изолировать металлические дорожки межсоединений,
избегая диэлектрического пробоя из-за слишком тонкого слоя изоляции
между ними. Сама же изоляция должна быть тонкой, т. к. иначе невозможно
подвести дорожки к всё время уменьшающимся транзисторам, кроме как
сделав такими же малыми и проводники, и разделяющие их изоляторы. К
низкопроницаемым материалам относятся диоксид кремния-углерода
(органосиликатное стекло с k=3 — самый популярный диэлектрик,
используемый с 90 нм), он же, но пористый (k=2,7), нанокластерный кварц
(2,25) и некоторые органические полимеры (k<2,2). По идее, изолятор,
разделяющий затвор и канал транзистора, должен подчиняться этим же
требованиям, но на деле оказывается всё наоборот — тут нужен как раз
высокопроницаемый диэлектрик.
Всё дело в эффекте квантового туннелирования. К 90-нанометровому
техпроцессу толщина затвора уменьшилась до величины от 1,2 (у Intel) до
1,9 нм (у Fujitsu; обе цифры — для n-каналов). А толщина кристаллической
решётки кремния, напомним, равна 0,543 нм. При такой тонкости электроны
начинают туннелировать сквозь изолятор, приводя к утечке тока. Дело
обстояло настолько серьёзно, что для техпроцесса 65 нм уменьшились все
параметры транзистора, кроме толщины затвора, т.к. если бы его сделали
ещё тоньше, то ни о какой энергоэффективности не стоило бы и мечтать.
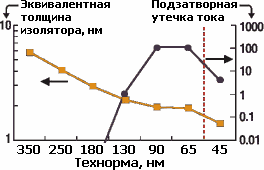
График толщины подзатворного изолятора в SiO2-эквиваленте и
относительной утечки тока. Введение высокопроницаемых изоляторов для
техпроцесса 45 нм позволило уменьшить эквивалентную толщину для
улучшения скорости, увеличив физическую толщину для уменьшения утечек.
Высокопроницаемый диэлектрик позволяет электрическому полю затвора
проникать на большую глубину или толщину, не снижая остальные
электрические характеристики, влияющие на скорость переключения
транзистора. Так что, заменив применявшийся с 90-х гг. оксинитрид
кремния на новый оксинитрид кремния-гафния (HfSiON, k=20–40) толщиной в 3
нм, для процесса 45 нм удалось уменьшить утечки тока в 20–1000 раз. Для
получения такой же скорости работы старый затвор пришлось бы делать
толщиной в 1 нм, что было бы катастрофой. Встречающиеся сегодня цифры
толщин подзатворных изоляторов менее чем в 1 нм являются как раз такими
SiO2-эквивалентами и применяются только для вычисления частоты, но не
утечки. Диоксид кремния, впрочем, до сих пор имеется в виде нижнего
подзатворного слоя, но используется только как физический интерфейс для
совместимости с текущими техпроцессами.
Любопытно, что при анонсе нового материала Intel поблагодарила
старого микроэлектронного соперника — IBM. Но не потому, что инженеры
«синего гиганта» разработали для коллег с не менее синим логотипом новый
материал — а потому, что детальное математическое моделирование,
доказавшее, что именно гафний является оптимальным материалом, провели
на суперкомпьютере IBM. Учитывать пришлось не только проницаемость, но и
ширину запрещённой зоны (она должна быть согласована с кремнием),
морфологию слоя, термостабильность, ненарушение высокой подвижности
носителей заряда в канале и минимальность краевых дефектов.
Впрочем, одного недостатка избежать не удалось: гафниевый
изолятор не совместим с поликремниевым затвором, так что пришлось менять
и его — на металлический. Теперь ясно, почему эти две технологии идут
парой. Однако новый затвор не алюминиевый, как это было в 60-х, а в виде
сплава двух металлов. Его сопротивление ниже, что ускоряет переключение
транзистора. Изначально было известно лишь то, что сплав отличается для
p- и n-канальных транзисторов, причём Intel (которая первой всё это
применила) держит оба состава в строгом секрете. Однако через год (в
2008-м) инженеры IBM (работа которых с тех пор используется в т.ч. на
заводах GlobalFoundries, ранее принадлежавших AMD) сделали свою версию
этой технологии, так что деталями пришлось делиться и Intel.
До сих пор использованию металлов мешал тот факт, что после
имплантации примесей пластина проходит отжиг при температуре 900–1000
°C, что выше температуры плавления многих металлов (включая алюминий) и
сплавов, но не поликремния. Хотя даже и без плавления при повышении
температуры металл может диффундировать в подлежащие слои. Теперь ясно,
почему точная формула сплавов держится в секрете — их действительно
трудно подобрать. Не зря лично Гордон Мур назвал HKMG наибольшим
достижением с момента изобретения поликремниевого затвора в 1969 г. До
этого момента алюминиевые затворы никому не мешали, т.к. не было ни
высокотемпературного отжига, ни формирования истоков и стоков впритык к
затворам. Сегодня же приходится применять всё более экзотические
материалы — например, Panasonic легирует сплав для n-каналов своих
HKMG-транзисторов редкоземельным элементом лантаном.
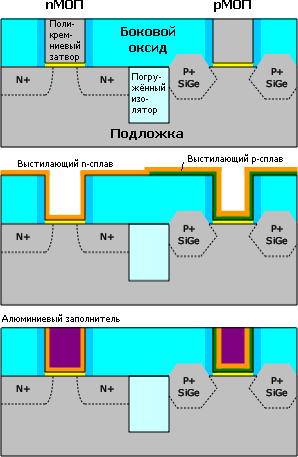 
Варианты реализации металлического затвора — последним (слева, Intel)
или первым (справа, общий случай). Стадии травления и полировки не
показаны; также не указан барьерный слой между подзатворным изолятором и
самим затвором (у Intel — TiN и TiAlN для p- и n-каналов, у GF — AlO).
Версия IBM и GF для всех транзисторов использует одинаковые заполнитель
(NiPtSi) и даже рабочий «металл» (TiN) — но для n-каналов они легируется
мышьяком.
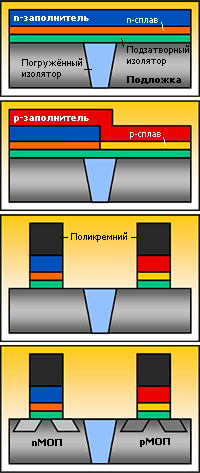
Не меньше вопросов возникает при обсуждении двух версий технологии.
Intel сначала формирует обычный поликремниевый затвор, работающий лишь
как маска для создания истока и стока, затем вытравливает его, осаждает
сплав для p-каналов, удаляет его из n-транзисторов, осаждает сплав для
n-каналов и добавляет ко всем затворам алюминиевый заполнитель — этот
вариант называется Gate last, «затвор последним». IBM и GF используют
Gate first, «затвор первым»: на подзатворный изолятор осаждается
p-сплав, удаляется над n-каналами, осаждается n-сплав, удаляется над
p-каналами, осаждается поликремний в качестве заполнителя и маски — а
далее как обычно.
Intel утверждает, что её версия лучше совместима с напряжённым
кремнием (потому что ему не мешает металл затвора) и позволяет
использовать большее разнообразие металлов (потому что они осаждаются
после высокотемпературных обработок), тогда как у конкурентов сложнее
получить разные виды транзисторов (по нагрузке, скорости, напряжению и
пр.), и они всё равно окажутся чуть медленнее и с меньшим выходом
годных. IBM и GF отвечают, что их способ дешевле и требует меньших
ограничений на расположение транзисторов, что позволяет разместить их на
10–20% плотней, а в Intel приходится мириться с жёсткими ограничениями
на размеры и расположение. Причём Intel тут в меньшинстве, потому что
«затвор первым» формируют и в Chartered, Freescale, Infineon и Samsung.
Последняя, правда, недавно заявила, что для её 20-нанометрового процесса
затвор всё же будет «последним».
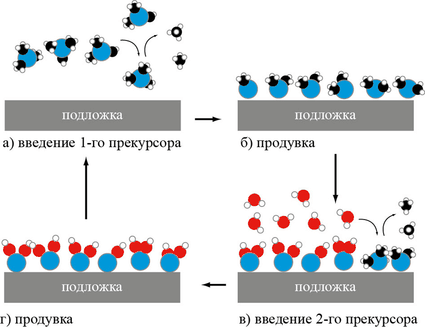
4 стадии цикла молекулярного наслаивания AlO2. Алюминий (синие атомы)
поставляет 1-й прекурсор, валентные связи которого заняты лигандами
(временными радикалами, в данном случае метильными группами —CH3). 1-я
продувка удаляет метан (CH4) и избыток прекурсора. Вторым прекурсором
является вода, замещающая остальные два лиганда у каждого атома Al. 2-я
продувка удаляет лишнюю воду и метан. В следующем цикле атомы водорода
1-го слоя будут замещены связью с Al 2-го слоя, восстановив свободные
метильные группы до метана.
Формирование широко применяемых в современных чипах тонких плёнок
было бы невозможно без технологии молекулярного наслаивания, она же —
послойное атомное осаждение (Atomic Layer Deposition, ALD). Её суть
заключается в том, что за один цикл обработки, длящийся всего несколько
секунд, образуется ровно один слой молекул, так что толщину
откладываемой плёнки можно регулировать с максимальной возможной
точностью (для самых простых веществ — ±10 пм) лишь числом циклов.
Каждый цикл состоит из двух стадий осаждения из газовой фазы прекурсоров
(химических предшественников осаждаемого вещества) и двух продувок для
удаления излишков. Прекурсоры подбираются так, чтобы лишь один их слой
мог прилипнуть к уже осаждённому материалу — к подложке для 1-го
осаждения, к предыдущему слою для нечётных осаждений (после 1-го) или к
первому прекурсору для чётных. Способ подходит не только для составных
веществ, но и для некоторых чистых металлов.
Молекулярное наслаивание впервые опробовано в начале 60-х
профессором Станиславом Кольцовым из Ленинградского Технологического
Института имени Ленсовета (ныне — СПбГТИ), а сама идея предложена
профессором Валентином Алесковским в 1952 г. в его докторской
диссертации «Остовная гипотеза и опыт синтеза катализаторов». Во всём
остальном мире наслаивание появилось лишь в 1977 г. под именем «Atomic
Layer Epitaxy» (ALE). Однако до микроэлектронного применения дело дошло
лишь в середине 90-х — до этого очень тонкие плёнки были не нужны.
Сейчас же, когда отдельные части транзистора исчисляются единичными
атомными слоями, без ALD не обойтись. Тем страннее то, что в русской
части Википедии об этой технологии и её создателях не написано вообще
ничего, да и в остальном рунете — с гулькин нос…
Расскажем и о двух любопытных техниках, применяемых лишь
некоторыми компаниями. Впрочем, первая известна с начала 2000-х и в
какой-либо форме применяется во всех современных сканерах — структурный
свет (structured light), меняющий форму луча лазера. Его сечение при
этом оказывается не круглым, а кольцевым, 4-полюсным или каким-то ещё.
Однако в 2009 г. Toshiba и NEC использовали в своём 32-нанометровом
процессе новый вид такого освещения (возможно, в комплексе с доводкой
методов OPC под него), что позволило обойтись без дорогостоящего
двойного структурирования (которое у этих фирм вызвало 25-процентное
увеличение дефектности). Обычно на таких размерах одно экспонирование
единственной маски на слой приводит к сильным искажениям прямых дорожек
(не смотря на OPC). Но структурный свет решает эту проблему и даже
позволяет уменьшить шаг между элементами. Поэтому у Toshiba и NEC
получилась самая маленькая (среди 32-нанометровых процессов всех фирм)
ячейка СОЗУ — на 0,124 мк² (позже мы сравним эти цифры детальней), а
плотность транзисторов в логике — 3,65 млн. вентилей/мм². И всё это по
вдвое меньшей удельной цене, чем для своих же 45 нм, и на 9% дешевле,
чем с применением двойного структурирования. Учись, Intel :)
В том же 2009 г. IBM реализовала в массовом производстве
технологию воздушных зазоров (Airgap) в качестве внутрислойных
изоляторов, разделяющих медные проводники одного слоя. Состоит такой
диэлектрик из тонкостенных пузырей размером в 20 нм, стенки которых
собираются из полимера методом самосборки. Пузыри содержат, вопреки
названию, не воздух, а вакуум — идеальный изолятор с проницаемостью,
равной 1 (впрочем, у воздуха почти столько же). По заявлению IBM, с
уменьшением межпроводной ёмкости чип потребляет на 35% меньше энергии
или работает на 15% быстрее. Впрочем, почувствовать это могли лишь
покупатели серверов IBM с ЦП архитектуры POWER. «Могли», потому что в
32-нанометровом процессе IBM воздушные зазоры исчезли — видимо,
механическая прочность «дырявого» слоя оказалась слишком малой для его
достаточно низкодефектной планаризации.
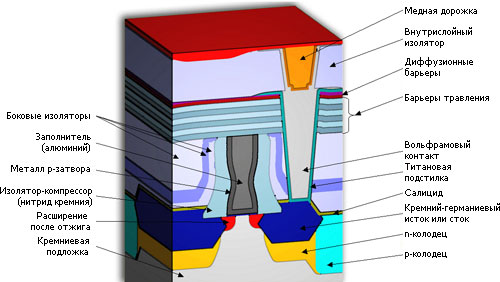
Пример современного техпроцесса
Устройство 45-нанометрового p-канального транзистора в микросхемах
Intel. Тут не указано присутствие в затворе слоя металла для
n-канального транзистора.
Чтобы подытожить всё вышенаписанное, приведём описание «скоростного»
45-нанометрового техпроцесса Intel как одного из наиболее изученных:
- используется пластина из цельного кремния (не КНИ) и сухая литография на 193 нм с двойным шаблонированием;
- длина затвора — 35 нм (как и в 65-нанометровом процессе);
- шаг затвора — 160 нм без изоляторов (на 27% меньше, чем в 65-нанометровом) и 200 нм с ними (на 9% меньше);
- осаждение металлического «затвора последним»;
- спрямление углов затвора с помощью покрытия вторым видом фоторезиста;
- эквивалентная толщина высокопроницаемого подзатворного изолятора — 1 нм;
- для улучшения подвижности дырок у p-канальных транзисторов
легирование германием истока и стока увеличено с 23 до 30%, что в
совокупности увеличило частоту на 51%;
- сонаправленные по всему чипу каналы;
- 10-слойные межсоединения (начиная со 2-го слоя — медные) с
изолятором из легированного углеродом диоксида кремния, включая
размещённый на истоках и стоках «нулевой» слой вольфрама, также служащий
диффузионным барьером;
- почти везде чётные слои металла параллельны каналам, нечётные — перпендикулярны;
- последний, наиболее толстый слой металла работает как термо- и энергораспределитель для всего кристалла;
- обильное использование фиктивных структур (дорожек и затворов) для выравнивания локальной плотности и теплопроводности;
- бессвинцовая пайка кристалла в корпус.

4 последних поколения транзисторов Intel (слева направо, сверху вниз) —
90 (2003 г., первое применение напряжённого кремния), 65 (2005), 45
(2007, первое применение комбинации HKMG) и 32 (2009) нм.

65-нанометровые транзисторы (слева) могли себе позволить такие
роскошества как двунаправленные дорожки (вертикали и горизонтали) и
переменные размеры затворов и их шагов. Для 32-нанометрового техпроцесса
(справа) всё это запрещено.
Общим взглядом.
Данные с IC Knowledge, если не указано иное.
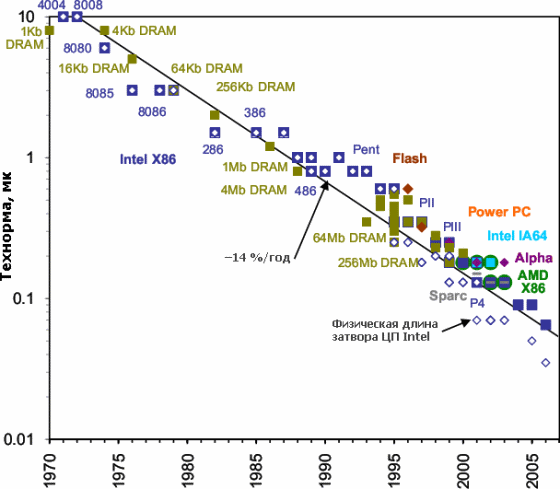
Технорма наиболее сложных микросхем. Падает также их цена — правда, не
вдвое (исходя из примерно половинной площади чипа для данного числа
транзисторов — за исключением последних техпроцессов…), а примерно в 1,5
раза при каждом переходе на очередной техпроцесс (т.к. он сложнее и
дороже на каждую единицу площади). По какой причине физическая длина
затвора (не только для ЦП Intel) оказывается меньше технормы — читайте
ниже.
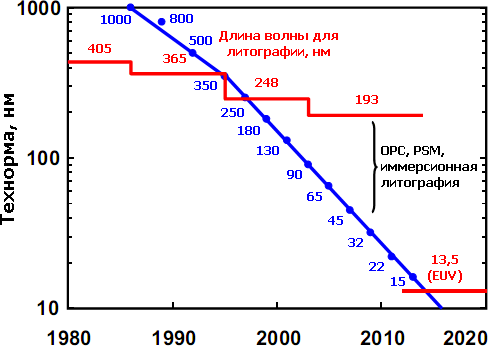
Технорма для ЦП Intel. По мнению компании, 15-нанометровый техпроцесс,
возможно, станет первым, где будет применяться «экстремальный»
ультрафиолет (EUV), если он окажется экономически оправданным. До сих
пор чрезвычайная дороговизна (даже по меркам фотолитографов) сдерживала
его внедрение, которое 10 лет назад пророчили уже для 45-нанометрового
процесса. Основные причины — необходимость в совершенно новом источнике
излучения, новой зеркальной (а не линзовой) оптике и полном вакууме в
рабочей зоне.
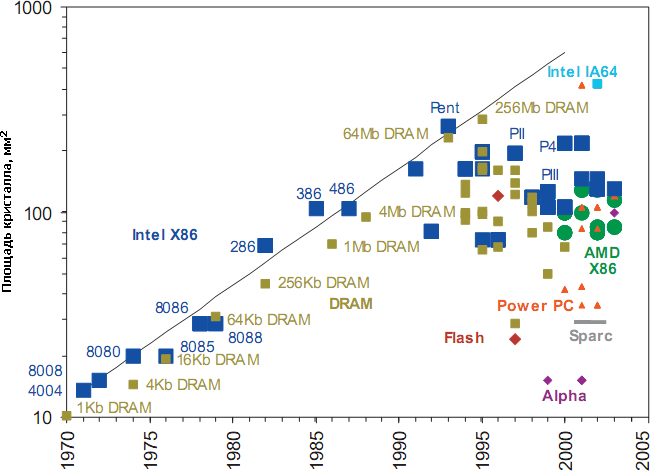
Площади кристаллов наиболее сложных микросхем процессоров и памяти на
указанный год. В 1990-е годы тенденция увеличения площади на 14% в год
(чёрная линия) остановлена. Впрочем, самые сложные кристаллы ГП и
серверных ЦП достигают 400–500 мм², но и эта цифра не растёт уже лет
пять, хотя почти все производители уже успели с 90-х перейти на
300-миллиметровые пластины, позволяющие производить с той же массовостью
и ценой даже такие большие кристаллы.
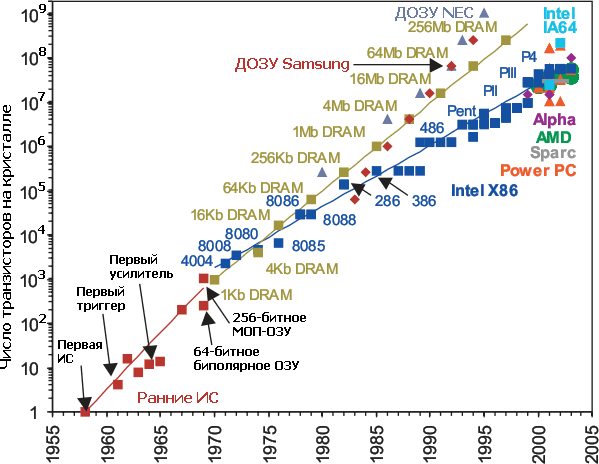
Число транзисторов на кристалле ИС как следствие уменьшения технормы и
увеличения площади кристалла. Видно, что первоначальная тенденция
2-кратного роста в год, по которой строил свои рассуждения Гордон Мур,
была в прямом смысле весьма крутой. Но с 70-х и микросхемы ДОЗУ (теперь —
и флэша), и процессоры продолжили её с меньшими темпами — 58% и 38% в
год.
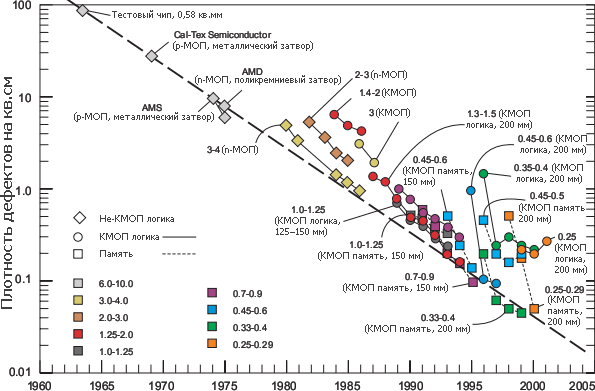
Плотность дефектов на 1 см² площади кристалла от наиболее продвинутых
фабов при финальном тестировании. Жирными цифрами указана технорма в
микронах, в скобках — диаметр пластин.
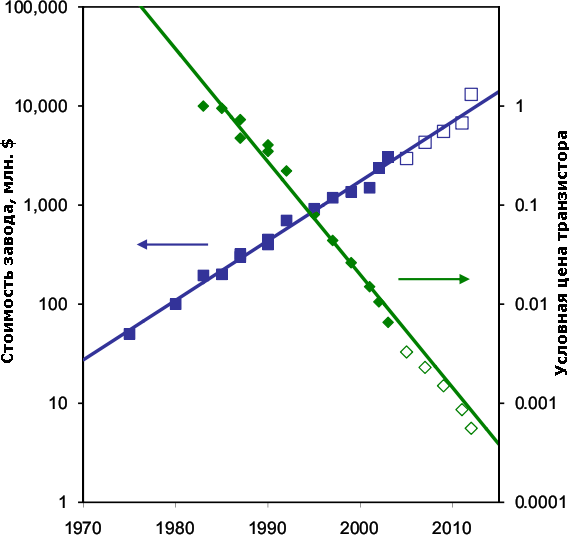
Стоимость постройки наиболее современного на указанный год завода (или
его стоимость после обновления) возросла в 70 раз за 30 лет, а цена
каждого выпускаемого ими транзистора упала в 2000 раз. Пустые квадраты
означают примерные цифры. Тут не хватает графика производственной
мощности, но надёжных данных по ней на весь период нет. Впрочем,
известно, что современные фабы выпускают от 10 до 60 тыс. пластин в
месяц в случае логики и ещё в 2–3 раза больше для памяти. Выпуск пластин
удваивается примерно каждые 5 лет, помимо увеличения их диаметра. А
«удвоение стоимости фаба каждые 4 года» даже было названо «вторым
законом Мура» (иначе — законом Рока, Rock’s law), который в конце 90-х
также пришлось поправить — каждые 5 лет. Наиболее дорогой станок —
фотолитограф — дорожает с такой же скоростью: первый коммерческий
проекционный степпер (1973 г.) стоил 210 тыс. долларов, а современный
сканер — 40–50 млн..
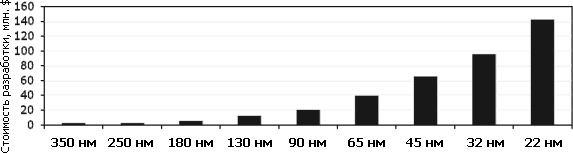
Стоимость разработки сложной микросхемы в зависимости от технормы
(данные IBS, GlobalFoundries). Видно, что до 45 нм она каждый раз
удваивалась, а начиная с 45 нм — увеличивается примерно в 1,5 раза.
Абсолютные цифры уже выросли настолько, что и среди бесфабричных
компаний мелким игрокам на рынке ЦП делать нечего.
Новый шаг
В начале лета 2011 г. Intel объявила, что менее чем через год
будет готова массово выпускать процессоры с технормой 22 нм (сначала это
будет архитектура Ivy Bridge, основанная на современной Sandy Bridge).
Согласно принятому в компании 2-летнему циклу «тик-так» (попеременному
ежегодному выпуску новой микроархитектуры и нового техпроцесса)
изначально планировалось выпустить Ivy Bridge в конце 2011 г. (также как
Sandy Bridge — в 2010-м). Однако Intel преследуют задержки: презентация
Sandy Bridge состоялась только этим январём, а недавно компания решила
задержать выход Ivy Bridge как минимум до весны 2012 г.Являются ли тому
причиной сложности с техпроцессом — неясно. Это при том, что первые
микросхемы СОЗУ с новыми 22-нанометровыми транзисторами Intel
представила ещё в сентябре 2009 г..
Никаких технологических революций по части литографических
методов не предвидится — помимо того, что длина волны 193 нм требует
иметь не только иммерсионные сканеры, но и как минимум двойное
шаблонирование. Это само по себе является любопытным, ибо ещё 5 лет
назад эксперты в один голос говорили, что для таких длин волн надо
переходить на новые виды литографии, что скачкообразно увеличивает
сложность и стоимость техпроцесса.
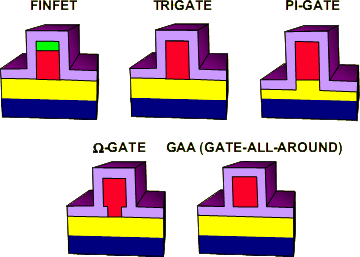
Помимо FinFET’ов, Intel рассматривала ещё 4 варианта новых видов
транзисторов, но по разным причинам они были отклонены. Например,
технически самый совершенный GAA-транзистор с затвором, полностью
окружённым изолятором, видимо, показался слишком дорогим или ненадёжным.
Кроме того, т.к. странная зелёная «шапка» ни на каких других
иллюстрациях больше не встречается и не видна на микрофотографиях, можно
сделать вывод, что реализован вариант с 3-сторонним затвором типа
Trigate.
Но самую большую сенсацию (разумеется, с подачи маркетологов
компании) назначили на серьёзное изменение конструкции транзисторов,
назвав их трёхмерными или трёхзатворными. Точнее, их надо называть
FinFET — полевой транзистор с затвором-«плавником». Впрочем, за счёт
утончения канала и размещения его вертикально их число может быть более
одного для увеличения общей площади между затвором и каналами. Такой
транзистор можно назвать многозатворным (multigate FET, MuGFET), хотя
каждый его канал скорее будет управляться общим затвором. В результате к
нему нужно будет приложить меньшее напряжение, чтобы переключить
транзистор, скорость переключения будет больше, а утечка — меньше, т.к.
теперь она возможна лишь через узкую нижнюю грань канала.
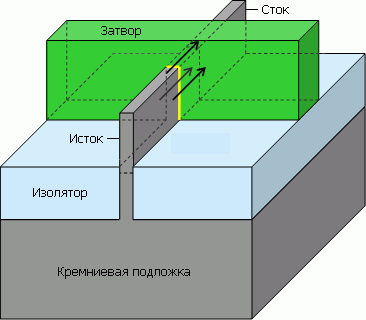
«Трёхзатворный» транзистор на деле означает транзистор с каналом,
окружённым затвором (через прослойку в виде тонкого изолятора,
обозначенного жёлтым) с трёх сторон — по сравнению с планарным, где
поверхность сопряжения представляет собой одну плоскость.
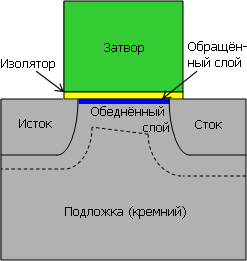
Транзистор на цельной подложке (какую до сих пор использует Intel) имеет
утечку тока из канала, когда в нём полем затвора формируется обращённый
слой. Подложка (даже если она заземлена) вытягивает часть носителей
заряда в обеднённый слой.
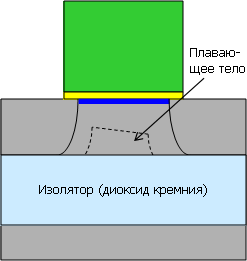
Уменьшить утечки можно технологией КНИ, в данном случае — частично
обеднённой (Partially Depleted, PD SOI). Тут изолятор отсекает подложку,
но остаточный слой под каналом («плавающее тело») всё ещё приводит к
утечкам, хоть и не таким большим. Эта технология широко используется
прежде всего из-за относительной дешевизны.
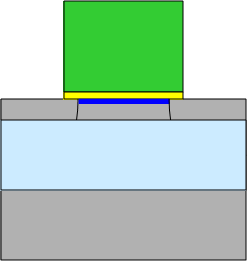
Более продвинутая версия — полностью обеднённый КНИ (Fully Depleted, FD
SOI). Тут исток, сток и область канала истончаются так, что плавающему
телу не остаётся места. Проблема утечки решается, но (по мнению Intel) с
10-процентным увеличением цены чипа, поэтому её не используют широко.
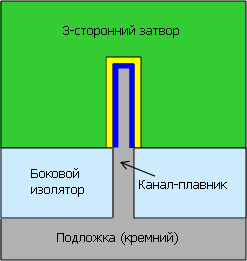
А вот и решение Intel (показанное сбоку, в отличие от предыдущих сечений
вдоль канала) — поставить канал вертикально и окружить его затвором с
трёх сторон из четырёх. Плавающего тела нет, утечек нет, площадь
обращённого слоя больше, а т.к. дополнительные маски не требуются, цена —
всего на 2–3% выше. Опять же, со слов Intel.

Вверху показаны 32-нанометровые планарные транзисторы, внизу —
22-нанометровые 2- (в левом нижнем углу) и 6-затворные «трёхмерные».

4 поколения «плавниковых» транзисторов Intel — демонстрация конструкции
(2002 г.), многозатворность (2003), ячейки СОЗУ (2006) и адаптация
металлического «затвора последним» (2007).
Конечно, Intel сразу похвасталась, что по сравнению с 10-микронным
техпроцессом от i4004 22-нанометровый транзистор работает в 4000 раз
быстрее, потребляя в 5000 меньше энергии и стоя в 50 000 меньше. Более
важно, что потребовалось 5 лет для разработки и ещё 5 (как теперь
выяснилось…) для адаптации к массовому производству. При этом Intel
честно указывает на трудности реализации новой технологии: необходимость
законцовок для затвора, проблемы с ёмкостью и изменчивостью параметров,
трудности равномерной полировки и травления более толстых структур и
передача каналом механического напряжения под затвор, и пр.. Надо
полагать, все эти проблемы решены хотя бы удовлетворительно, иначе
показанные чипы бы не работали. Вопросы о коэффициенте выхода годных и
фактической себестоимости пока остаются открытыми. Конкуренты же (TSMC и
Global Foundries) пока объявили лишь о начале разработки FinFET’ов для
своих 14-нанометровых процессов, которые будут готовы где-то в 2014 г.…
Разбор нанометров
Самое время разобраться, что понимается под технормой. Попытка
дать определение этому важнейшему термину не зря поставлена почти в
конец статьи. Когда-то под технормой понимался самый малый по длине или
ширине элемент, формируемый данным техпроцессом. Когда технорма стала
меньше длины волны, появилось два отдельных определения — для регулярных
чипов (память, программируемые матрицы, фотодатчики — в т.ч. со
встроенными логическими блоками) и нерегулярных (сложная логика, в т.ч.
содержащая кэши, буферы и т.п.). Для первых — минимальный полушаг
линейно-регулярной структуры, для вторых — минимальная ширина дорожки
нижнего уровня металла (что примерно вдвое длиннее затвора транзистора).
Однако с недавних пор и это перестало иметь значение. Дело в том,
что число фабрик, производящих микросхемы по самым современным
техпроцессам, неуклонно снижается. При этом ни одна фирма, производящая
оборудование для производства полупроводников, их самих не делает — все
производители микросхем покупают станки у примерно одних (тоже не очень
многочисленных) фирм. Очевидно, собираемые из станков и настроек
техпроцессы на фабах получились бы как две капли воды похожи, но это
имеет смысл лишь для нескольких фабов одной компании, а таких компаний в
мире — единицы. Так что каждая фирма пытается удовлетворить заказчиков
чем-то особенным, выпускаемым на почти стандартном оборудовании. И вот
тут под нож пошли те самые нанометры…
Более того, ITRS (International Technology Roadmap for
Semiconductors — международный технологический план для [производителей]
полупроводников, составляемый экспертами из крупнейших фирм и их
ассоциаций) регулярно выпускает рекомендации по основным параметрам
техпроцессов для микроэлектронных компаний, т.е. для самих себя.
Краткий ответ — никак. Дело дошло до того, что на недавнем форуме
IEDM технорму признались считать маркетинговым понятием — т.е. не более
чем цифрой для рекламы. Фактически, сегодня сравнивать техпроцессы по
нанометрам стало не более разумно, чем 10 лет назад (после выхода
Pentium 4) продолжать сравнивать производительность ЦП (пусть даже и
одной программной архитектуры) по гигагерцам.
Разница в техпроцессах при одинаковых технормах активно влияет и
на цену чипов. Например, AMD использовала разработанный совместно с IBM
65-нанометровый процесс с SOI-пластинами, двойными подзатворными
оксидами, имплантированным в кремний германием, двумя видами напряжённых
слоёв (сжимающим и растягивающим) и 10 слоями меди для межсоединений.
65-нанометровый техпроцесс у Intel включает относительно дешёвую
пластину из цельного кремния, диэлектрик одинарной толщины,
имплантированный в кремний германий, один растягивающий слой и 8 слоёв
меди. По примерным подсчётам Intel потребует для своего процесса 31
маску, а AMD — 42.
В результате из-за значительной разницы в технологиях
напряжённого кремния и типа подложки (SOI-пластины стоят примерно в 3,6
раз дороже простых) конечная цена 300-миллиметровой пластины для AMD
будет ≈4300 долларов, что на 70% дороже цены для Intel — ≈2500 долларов.
Кстати, ЦП Intel как правило оказываются ещё и с меньшими площадями
кристаллов, чем аналогичные по числу ядер и размеру кэшей от AMD. Теперь
ясно, почему Intel показывает завидную прибыль, а AMD недавно едва
держалась на ногах.
По докладам на IEDM можно составить сводную таблицу с параметрами
последних техпроцессов ведущих компаний. Из неё видно, что все
техпроцессы с «мелкой» технормой (process node) перешли на двойное
шаблонирование (DP) и иммерсионную литографию, а напряжение питания
(Vdd) давно остановилось на 1 вольте (потребление транзистором энергии и
без этого продолжает падать, но не так быстро). Куда интересней
сравнить длину затвора (LGate), шаг затвора с контактом (Contacted Gate
Pitch) и площадь ячейки СОЗУ (SRAM Cell Size).
Тут надо указать, что кэши изготовленного с той же технормой ЦП
той же фирмы имеют площадь ячейки на 5–15 % больше указанной в случае L2
и L3, и на 50–70 % больше для L1. Дело в том, что сообщаемые на IEDM
цифры площади тоже являются несколько рекламными. Они верны лишь для
одиночного массива ячеек и не учитывают усилители, буферы ввода-вывода,
декодеры адреса, резервы размера для увеличения надёжности и размены
плотности на скорость (для L1).
Для простоты возьмём только «скоростные» (High Performance)
процессы Intel. Для 130 нм длина затвора составляла 46% технормы, а
сегодня — 94%. Тем не менее, шаг затвора уменьшился в те же 4 раза, что и
технорма. Однако если разделить площадь ячейки СОЗУ на квадрат
технормы, то старым ячейкам нужно ≈120 таких квадратиков, а новым — уже
≈170. У AMD с её SOI-пластинами — примерно так же. На «65-нанометровом»
техпроцессе фактический минимальный размер затвора может быть снижен до
25 нм, но шаг между затворами может превышать 130 нм, а минимальный шаг
металлической дорожки — 180 нм. Начиная примерно с 2002 г. размеры
транзисторов уменьшаются медленней технорм. Выражаясь языком
современного рунета — нанометры уже не те…
А теперь, вооружившись цифрами об этом бардаке сложном
микроэлектронном хозяйстве, вернёмся к обещанным Intel «22 нанометрам».
По предварительным цифрам выглядит неплохо: площадь ячейки — 0,092
кв.мк. для «быстрой» и 0,108 для энергоэффективной версии процесса
(данные 2009 г. для тестовой микросхемы СОЗУ на 22 нм). Для быстрой
версии это эквивалентно 190 элементарным квадратам — чуть хуже, чем для
прошлых технорм. Но Intel продолжит использовать 193-нанометровую
иммерсионную литографию и для 14 нм, возможно — с тройным
шаблонированием. А для 10 нм — с пятерным (5 экспозиций и одно
скругление распорок). При этом для 10-нанометрового процесса стоимость
стадий литографии на единицу площади будет примерно вшестеро больше, чем
для 32-нанометрового, а вот окажется ли площадь меньше в 10 раз (как
при линейном уменьшении) — сомнительно. Тут уже даже неважно, почему
Intel решила, что следующие два её процесса будут иметь технормы 14 и 10
нм, а не 16 и 11, как можно ожидать (каждая следующая — в √2 раз
меньше). Ведь нанометры теперь мало что значат…
Что дальше?
Если вернуться к обзорным графикам, последние несколько из них не
зря касаются цены или себестоимости. Если по ним попытаться
экстраполировать тенденции на будущее, то окажется, что через некоторое
время в мире останется лишь 2–3 компании, способные разрабатывать и
внедрять самые современные техпроцессы. Им это будет влетать в
11-значные суммы в долларах, окупить которые можно, лишь если продукция
будет продаваться по всему миру, что возможно только при полной
монополизации — одна платформа, одна архитектура, одна концепция… Для
необходимой конкуренции избыточности места уже не останется — нас всего 7
миллиардов, и это число растёт совсем не так быстро, как цены на фабы и
техпроцессы.
Более того, наверняка будет уменьшаться и число бесфабричных
компаний. Дело даже не в том, что немногие крупные фирмы покроют своими
чипами почти все потребности почти для всех. Даже если вы разработали
что-то уникальное — стоимость внедрения может оказаться такой высокой,
что вы не окупите её всеми своими продажами. И это тоже есть следствие
массовых технологий:
Формируемое маской изображение перед попаданием на пластину
оптически уменьшается в 4 раза до стандартной полосы засвета размером
≈24 мм (для современных литографов), а размер самой маски составляет
около 18×12 см. Однако методы OPC и PSM требуют от неё иметь разрешение
не хуже формируемого, что уже для 65 нм поднимает стоимость набора масок
до сотен тысяч долларов, а для самых новых техпроцессов — до пары
миллионов.
Теперь представим, что нам — маленькой, но гордой фирме — надо
выпустить систему-на-кристалле, разработанную для новых планшетов и
смартфонов. Маркетологи говорят, что из-за сильной конкуренции со
стороны угадайте-какой компании устройства с нашим ЦП точно купят 100000
человек. Процессор на 28-нанометровом техпроцессе (более старый
проиграет гонку прожорливости) будет иметь себестоимость около 15
долларов, но если учесть цену масок (пусть и разделённую на 100000), то
будет уже 35 долларов. И это не учитывая выпуск нескольких ревизий для
исправления ошибок и оптимизации параметров. Ревизий для нового сложного
чипа нужно штук пять — и для каждой (после первой) надо обновлять
значительную долю масок из всего набора.
В итоге окажется, что даже не допуская ни одной ошибки в рыночной
стратегии, мы окупим нашу микросхему, лишь рассчитывая на производство и
сбыт устройств с ней миллионами, иначе её никто не купит из-за цены.
Недавно сотрудник компании Cadence (выпускающей специализированные САПРы
для разработки микросхем) рассказал, что стоимость перехода с 32–28 на
22–20 нм сильно выросла по сравнению с предыдущими шагами.
Микроэлектронные компании инвестировали в НИОКР по 32–28 нм 1,2 млрд.
долларов и 2–3 млрд. для 22–20 нм. Проектирование чипа стоит 50–90 млн.
долларов для 32 нм и 120–500 млн. долларов для 22 нм. Компенсация затрат
на разработку и производство потребует продать 30–40 млн.
32-нанометровых кристаллов и 60–100 млн. на 20 нм.
Впрочем, и крупным компаниям, товары которых покупают как раз
миллионами, тоже придётся с трудом объяснять, зачем покупать очередной
процессор с терафлопсами и память на терабайты — учитывая, что и прошлые
модели делают всё как надо. Возможно, с некоторого момента не поможет и
принудительная плата за новинки — например, как следствие досрочно
отменённой поддержки старых моделей или их запрограммированного износа и
отключения…
Мировая микроэлектроника, следуя закону Мура, всегда опровергала
регулярно выдвигаемые инженерами опасения, что мы вот-вот упрёмся в
непреодолимые физические ограничения, после которых отрасль либо
застрянет навсегда, либо будет вынуждена перейти на принципиально новые
материалы и эффекты. Но как бы не оказалось так, что реальным тормозом
будет эффект глобального насыщения: после бурного роста менять каждые
год-два процессоры и память как обувь и одежду — на новые, подходящие
размеры — уже не потребуется.
Другая проблема в том, что даже в тех применениях, где
производительность и память никогда не будут лишними, качественный
скачок (вместо очередного удвоения регистров, векторов, кэшей и ядер)
может быть лишь при переходе на новый вид элементной базы — графеновой,
фотонной, спинтронной, квантовой или прочей «волшебной». Но для её
разработки, адаптации к массовому производству и (особенно!) построению
самого производства потребуется огромное количество денег — куда большее
цены современного фаба. Вполне возможно, лет через 10 (когда нынешнюю
литографию растягивать далее уже не получится) никакие частные фирмы это
не потянут. А какое из государств даже сегодня захочет профинансировать
высокорисковые технологии микроэлектроники будущего?
Источник: ixbt.com
|